はじめに
毎日のように見ているWebページですが、
ブラウザのアドレスバーにURLを入力してEnterキーを押すと、数秒もかからずWebページが表示されます。
普段はあまり意識しませんが、この短い時間の中では、実はいくつもの処理が順番に行われています。URLの解析、DNSによる名前解決、Webサーバへの接続、HTTPリクエストとHTTPレスポンス、HTML・CSS・JavaScriptの読み込みなど、Webページが表示されるまでには多くの仕組みが関わっています。
基本情報技術者試験でも、DNS、IPアドレス、HTTP、HTTPS、HTML、CSS、JavaScriptといった用語はよく登場します。ただ、それぞれの用語を個別に覚えているだけだと、「結局それらがWebページの表示とどう関係しているのか」が見えにくいかもしれません。
そこでこの記事では、ブラウザにURLを入力してから画面にWebページが表示されるまでの流れを、基本情報技術者試験レベルで整理していきます。
細かい通信プロトコルの仕様を深掘りするというよりも、まずは全体像をつかむことを目的にします。Webエンジニアとして実務で開発していると、画面が表示されない、API通信が失敗する、画像やJavaScriptが読み込まれない、といった場面に出会います。そのとき、裏側で何が起きているのかを大まかに理解していると、原因を切り分けやすくなります。
この記事を通して、基本情報で学ぶ知識を単なる暗記ではなく、実際のWeb開発につながる知識として理解していきましょう。
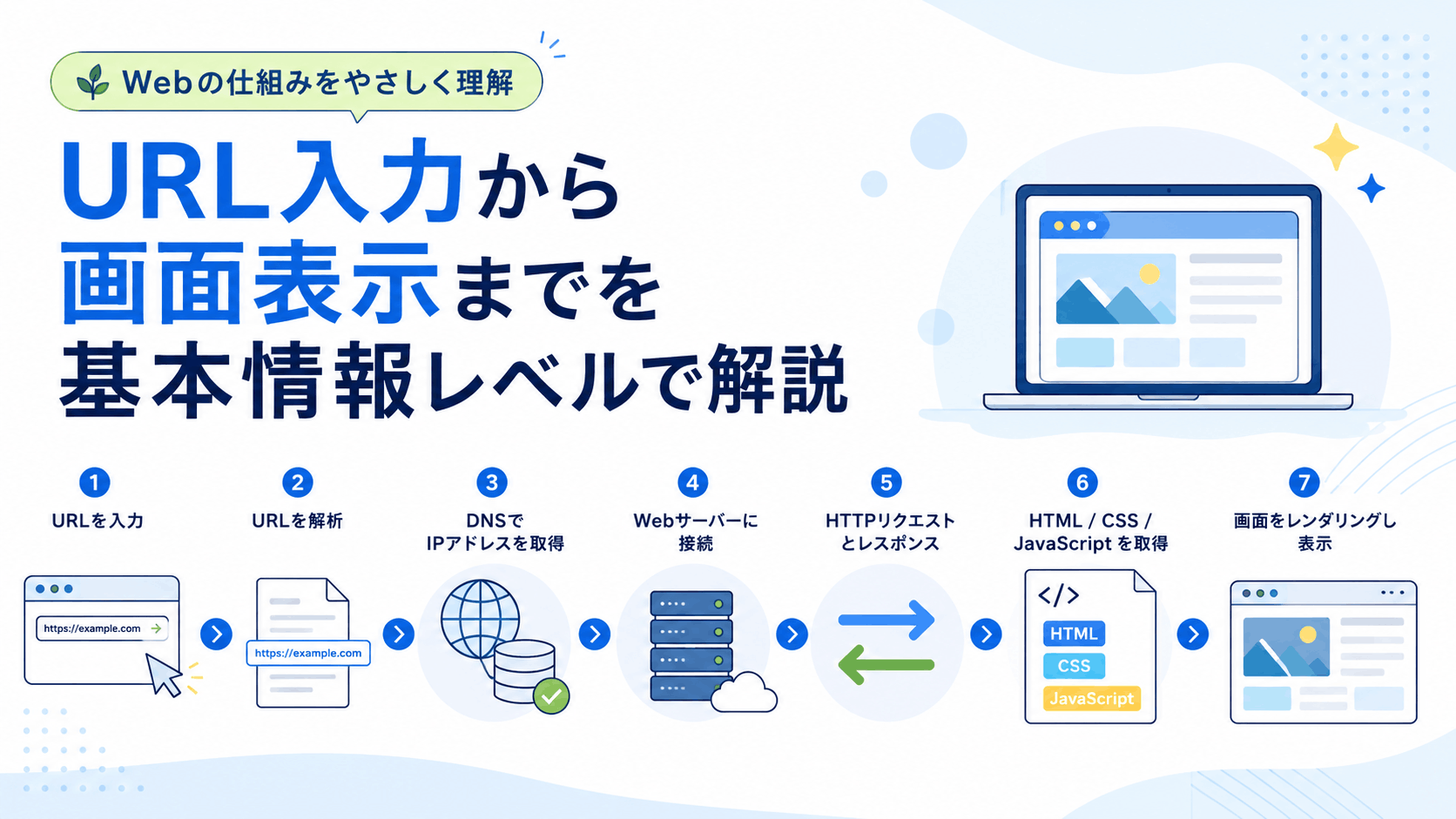
全体の流れ:URL入力から画面表示まで
まずは、ブラウザにURLを入力してからWebページが表示されるまでの流れを、大まかに見てみましょう。
たとえば、ブラウザのアドレスバーに次のようなURLを入力したとします。
https://example.com/articles
このとき、ブラウザの内部ではおおよそ次のような処理が行われます。
1. URLを入力する
2. URLを解析する
3. DNSでドメイン名からIPアドレスを調べる
4. Webサーバへ接続する
5. HTTPリクエストを送る
6. HTTPレスポンスを受け取る
7. HTML / CSS / JavaScriptを読み込む
8. ブラウザが画面に表示する

普段は「URLを入力したらページが開く」と一瞬で考えてしまいますが、実際にはこのように複数の処理が順番に行われています。
最初にブラウザは、入力されたURLを見て、どの通信方法を使うのか、どのサーバにアクセスするのか、どのページを取得したいのかを判断します。
たとえば、https://example.com/articles であれば、https は通信方法、example.com はアクセス先のドメイン名、/articles は取得したいページの場所を表します。
ただし、コンピュータ同士が通信するときには、基本的に example.com のような名前ではなく、IPアドレスが必要です。そこでブラウザはDNSという仕組みを使って、ドメイン名に対応するIPアドレスを調べます。これを名前解決といいます。
IPアドレスがわかると、ブラウザはWebサーバに接続します。そして、「このページをください」というHTTPリクエストを送ります。
リクエストを受け取ったWebサーバは、必要な処理を行い、HTMLなどのデータをHTTPレスポンスとして返します。ブラウザは受け取ったHTMLを読み取り、必要に応じてCSS、JavaScript、画像ファイルなども追加で取得します。
最後に、ブラウザがHTMLの構造、CSSによる見た目、JavaScriptによる動きを解釈し、私たちが見ているWebページとして画面に表示します。
この流れを理解しておくと、基本情報技術者試験で出てくるDNS、IPアドレス、HTTP、HTML、CSS、JavaScriptといった用語が、バラバラの知識ではなく、Webページを表示するための一連の仕組みとしてつながって見えるようになります。
以降の章では、この流れを1つずつ分解して見ていきます。
URLは何を表しているのか
Webページにアクセスするとき、私たちはブラウザにURLを入力します。
URLとは、インターネット上にある情報の場所を示すものです。Webページ、画像、CSSファイル、JavaScriptファイル、APIのエンドポイントなど、さまざまなリソースの場所を表すために使われます。
たとえば、次のURLを見てみましょう。
https://example.com/articles?id=10
このURLは、いくつかの部品に分けて考えることができます。
https → スキーム
example.com → ホスト名
/articles → パス
?id=10 → クエリ文字列
https は、どの通信方式を使うかを表します。Webページでは http または https がよく使われます。現在のWebサイトでは、通信内容を暗号化できる https が一般的です。
example.com はホスト名です。これは、アクセス先のサーバを人間がわかりやすい名前で表したものです。ただし、実際にコンピュータ同士が通信するときには、ホスト名そのものではなくIPアドレスが使われます。そのため、後ほど説明するDNSによって、ホスト名からIPアドレスを調べる必要があります。
/articles はパスです。サーバの中のどのリソースにアクセスしたいのかを表します。Webアプリケーションでは、このパスをもとに「記事一覧ページを表示する」「商品詳細ページを表示する」「APIの処理を実行する」といったルーティングが行われます。
?id=10 はクエリ文字列です。これは、サーバに追加の情報を渡すために使われます。たとえば、検索キーワード、ページ番号、商品ID、絞り込み条件などがクエリ文字列として渡されることがあります。
JavaScriptでは、URL オブジェクトを使うとURLを簡単に分解できます。
const url = new URL('https://example.com/articles?id=10');
console.log(url.protocol); // "https:"
console.log(url.hostname); // "example.com"
console.log(url.pathname); // "/articles"
console.log(url.searchParams.get('id')); // "10"
このように、URLは単なる文字列ではありません。
ブラウザやサーバはURLを分解し、「どの方法で」「どのサーバに」「どのリソースを」取りに行くのかを判断しています。
基本情報技術者試験では、URLやURIという用語が出てくることがあります。厳密にはURIはリソースを識別するための広い概念で、URLはそのリソースの場所を示すものです。ただし、最初の理解としては、Webページにアクセスするときに使う https://... の形がURLだと押さえておけば十分です。
URLの構造を理解しておくと、Web開発でも役立ちます。たとえば、APIのエンドポイントを設計するとき、画面遷移のルーティングを考えるとき、クエリパラメータを使って検索条件を渡すときなど、URLの知識は日常的に使われます。
次の章では、URLに含まれるホスト名から、実際に通信で使うIPアドレスを調べる仕組みであるDNSについて見ていきます。
DNS:ドメイン名からIPアドレスを調べる
URLの中にある example.com のような名前を、ドメイン名といいます。
人間にとっては、example.com や google.com のような文字のほうが覚えやすいですが、コンピュータ同士が通信するときには、基本的にIPアドレスが使われます。IPアドレスとは、ネットワーク上の機器を識別するための番号のようなものです。
たとえば、Webサーバにアクセスしたい場合、ブラウザは最終的に「どのIPアドレスのサーバに接続するのか」を知る必要があります。
そこで使われるのが DNS です。
DNSは、ドメイン名とIPアドレスを対応付ける仕組みです。example.com のようなドメイン名をもとに、それに対応するIPアドレスを調べます。
このように、ドメイン名からIPアドレスを調べることを 名前解決 といいます。
example.com
↓ DNSで名前解決
93.184.216.34
ブラウザにURLを入力すると、ブラウザやOSはまずキャッシュを確認します。以前に同じドメインへアクセスしたことがあれば、IPアドレスの情報が一時的に保存されている場合があります。
キャッシュに情報がなければ、DNSサーバに問い合わせて、ドメイン名に対応するIPアドレスを調べます。IPアドレスがわかってはじめて、ブラウザはWebサーバへ接続できるようになります。
つまり、DNSはWebページを表示するための最初の重要なステップです。
もしDNSの設定に問題があると、サーバ自体は正常に動いていても、ブラウザからWebサイトにアクセスできないことがあります。実務でも、「サーバは動いているのにドメインでアクセスできない」という場合は、DNS設定や名前解決を確認することがあります。
基本情報技術者試験では、DNSについて次のように押さえておくとよいです。
DNS → ドメイン名とIPアドレスを対応付ける仕組み
名前解決 → ドメイン名からIPアドレスを調べること
IPアドレス → ネットワーク上の機器を識別するための番号
なお、実際のDNSでは、ルートDNSサーバ、TLDサーバ、権威DNSサーバなど、複数のサーバが関わります。ただし、基本情報レベルでは、まず「DNSはドメイン名からIPアドレスを調べる仕組み」と理解しておけば十分です。
DNSによってIPアドレスがわかったら、次はそのIPアドレスを使ってWebサーバへ接続します。
サーバへ接続する:TCP/IPとHTTPS
DNSによってドメイン名に対応するIPアドレスがわかると、ブラウザはそのIPアドレスを使ってWebサーバへ接続します。
ここで関わってくるのが、TCP/IP というネットワーク通信の基本的な仕組みです。
TCP/IPは、インターネットで広く使われている通信のルールの集まりです。基本情報技術者試験でもよく出てくる重要な用語です。
Webページを見るとき、ブラウザとWebサーバはネットワークを通じてデータをやり取りします。そのとき、IPアドレスを使って通信相手を特定し、TCPによってデータを正しく届けるための通信を行います。
ブラウザ
↓ IPアドレスを使って接続
Webサーバ
IPアドレスは「どのコンピュータに送るか」を表す情報です。
一方で、ポート番号は「そのコンピュータのどのサービスに接続するか」を表します。
Webサイトでは、一般的に次のポート番号が使われます。
HTTP → 80番ポート
HTTPS → 443番ポート
たとえば、https://example.com/articles にアクセスする場合、ブラウザは example.com に対応するIPアドレスを調べたあと、そのサーバの443番ポートに接続します。
現在のWebサイトでは、ほとんどの場合 https が使われます。HTTPSは、HTTPの通信を暗号化したものです。通信内容を第三者に盗み見られたり、改ざんされたりしにくくするために、TLSという仕組みを使って安全な通信を行います。
基本情報レベルでは、まず次のように押さえておくとよいです。
HTTP → WebブラウザとWebサーバがデータをやり取りするためのプロトコル
HTTPS → HTTPをTLSで暗号化したもの
TCP → データを正しく届けるための通信方式
IP → 通信相手を特定するための仕組み
ここで大切なのは、URLに https と書かれている場合、ブラウザは単にHTMLを取りに行くだけでなく、まず安全に通信できる接続を準備しているという点です。
この接続ができてはじめて、ブラウザはWebサーバに対して「このページをください」というHTTPリクエストを送ることができます。
実務でも、Webサイトにアクセスできないときは、DNSだけでなく、サーバへの接続やポートの開放状況を確認することがあります。たとえば、DNSは正しく設定されているのにページが開けない場合、サーバが起動していない、443番ポートが閉じている、HTTPS証明書に問題がある、といった原因が考えられます。
ただし、この記事では細かいTCPの制御やTLSの詳しい手順までは扱いません。まずは、DNSでIPアドレスを調べたあと、ブラウザがTCP/IPを使ってWebサーバに接続し、HTTPSの場合は暗号化された通信を行う、と理解しておきましょう。
次の章では、接続ができたあとにブラウザからWebサーバへ送られる、HTTPリクエストについて見ていきます。
HTTPリクエスト:ブラウザからサーバへのお願い
Webサーバへの接続ができると、次にブラウザはサーバに対して「このページをください」という要求を送ります。
この要求のことを HTTPリクエスト といいます。
HTTPは、WebブラウザとWebサーバがデータをやり取りするためのプロトコルです。プロトコルとは、通信するときのルールのことです。つまりHTTPは、ブラウザとサーバが「どのような形式で依頼し、どのような形式で返事をするか」を決めているルールだと考えるとわかりやすいです。
たとえば、ブラウザで次のURLにアクセスしたとします。
https://example.com/articles
このとき、ブラウザはWebサーバに対して、おおよそ次のようなリクエストを送ります。
GET /articles HTTP/1.1
Host: example.com
User-Agent: Browser
GET はHTTPメソッドの1つです。GETは、サーバから情報を取得したいときに使われます。Webページを表示するときや、画像・CSS・JavaScriptファイルを取得するときにも、基本的にはGETリクエストが使われます。
/articles は、サーバに要求しているリソースのパスです。URL全体のうち、どのページやファイルが欲しいのかを表しています。
Host: example.com のような行は、HTTPヘッダと呼ばれます。HTTPヘッダには、アクセス先のホスト名、ブラウザの種類、受け取りたいデータ形式、Cookieなど、通信に必要な追加情報が含まれます。
JavaScriptでは、fetch を使うとHTTPリクエストを送ることができます。
const response = await fetch('https://example.com/articles');
console.log(response.status);
このコードでは、https://example.com/articles に対してGETリクエストを送り、その結果として返ってきたレスポンスを response に受け取っています。
フォーム送信やAPIへのデータ登録では、GET以外のHTTPメソッドも使われます。代表的なものには、POSTがあります。
GET → サーバからデータを取得する
POST → サーバへデータを送信する
たとえば、検索結果ページを開く、記事一覧を取得する、画像を読み込むといった処理ではGETが使われます。一方で、ログインフォームを送信する、問い合わせ内容を送信する、商品を注文する、といった処理ではPOSTが使われることが多いです。
基本情報技術者試験では、HTTPはWebブラウザとWebサーバ間の通信に使われるプロトコルとして押さえておきましょう。また、GETはデータ取得、POSTはデータ送信という大まかな違いも重要です。
実務では、ブラウザの開発者ツールを使うと、実際にどのようなHTTPリクエストが送られているかを確認できます。Networkタブを見ると、アクセス先URL、HTTPメソッド、リクエストヘッダ、ステータスコードなどを確認できます。
画面が表示されない、API通信が失敗する、フォーム送信がうまくいかないといった場面では、まずHTTPリクエストが正しく送られているかを確認することが、原因調査の第一歩になります。
次の章では、HTTPリクエストを受け取ったサーバが、ブラウザに返すHTTPレスポンスについて見ていきます。
HTTPレスポンス:サーバから返ってくるデータ
ブラウザがHTTPリクエストを送ると、Webサーバはそれに対する返事を返します。
この返事のことを HTTPレスポンス といいます。
HTTPリクエストが「このページをください」というお願いだとすると、HTTPレスポンスは「結果はこうです。必要なデータはこちらです」というサーバからの返答です。
たとえば、ブラウザが次のようなリクエストを送ったとします。
GET /articles HTTP/1.1
Host: example.com
これに対して、サーバは次のようなHTTPレスポンスを返します。
HTTP/1.1 200 OK
Content-Type: text/html
<!doctype html>
<html>
<head>
<title>Example</title>
</head>
<body>
<h1>Hello</h1>
</body>
</html>
HTTP/1.1 200 OK の 200 は、ステータスコードです。
ステータスコードは、リクエストの結果を表す3桁の数字です。
200 OK は、リクエストが成功したことを表します。つまり、ブラウザが要求したページやデータを、サーバが正常に返せたという意味です。
Content-Type: text/html は、返ってくるデータの種類を表します。この例では、HTMLが返ってくることを示しています。画像であれば image/png、JSONであれば application/json のように、レスポンスの内容によって種類が変わります。
Webページを表示するとき、最初に返ってくる代表的なデータはHTMLです。ブラウザはこのHTMLを読み取り、画面の構造を作っていきます。
基本情報技術者試験や実務でよく見るステータスコードには、次のようなものがあります。
200 → 成功
301 → 恒久的なリダイレクト
302 → 一時的なリダイレクト
404 → ページが見つからない
500 → サーバ内部のエラー
404 Not Found は、指定されたページやファイルが見つからない場合に返されます。URLのパスが間違っている、ファイルが削除されている、ルーティング設定が正しくない、といった場合に発生します。
500 Internal Server Error は、サーバ側で何らかのエラーが発生した場合に返されます。PHPやWebアプリケーションの処理で例外が発生した場合などに見ることがあります。
301 や 302 は、リダイレクトを表します。リダイレクトとは、アクセスしたURLとは別のURLへ移動させる仕組みです。たとえば、古いURLから新しいURLへ転送する場合や、ログインしていないユーザーをログインページへ移動させる場合などに使われます。
JavaScriptの fetch では、レスポンスのステータスコードやデータを確認できます。
const response = await fetch('https://example.com/articles');
console.log(response.status); // 例: 200
console.log(response.ok); // 200番台ならtrue
const html = await response.text();
console.log(html);
API通信の場合は、HTMLではなくJSONが返ってくることも多いです。
const response = await fetch('https://example.com/api/articles');
const data = await response.json();
console.log(data);
このように、HTTPレスポンスには、リクエストの結果を表すステータスコードと、実際にブラウザやJavaScriptが利用するデータが含まれています。
実務で画面が正しく表示されないときは、開発者ツールのNetworkタブでレスポンスを確認すると原因を見つけやすくなります。ステータスコードが404ならURLやルーティングの問題、500ならサーバ側の処理の問題、200でも表示がおかしいならHTMLやJavaScriptの処理に問題がある、というように切り分けできます。
HTTPレスポンスを受け取ると、ブラウザはその中に含まれるHTMLを解析し、Webページとして表示する準備を始めます。
次の章では、ブラウザがHTMLをどのように読み取り、画面を作っていくのかを見ていきます。
ブラウザはHTMLを解析して画面を作る
HTTPレスポンスとしてHTMLを受け取ると、ブラウザはそのHTMLを読み取り、Webページとして画面に表示する準備を始めます。
ここで大切なのは、HTMLがそのまま画像のように表示されるわけではない、という点です。ブラウザはHTMLの内容を解析し、タグの親子関係や文書の構造を理解してから画面を作ります。
たとえば、次のようなHTMLが返ってきたとします。
<!doctype html>
<html>
<head>
<title>Example</title>
</head>
<body>
<h1>Hello</h1>
<p>Webページの表示の仕組みを学びます。</p>
</body>
</html>
ブラウザはこのHTMLを上から順に読み取り、html 要素の中に head と body があり、body の中に h1 や p がある、という構造として理解します。
このように、HTMLをもとにブラウザ内部で作られる文書構造を DOM といいます。
DOMは、Document Object Modelの略です。
簡単に言うと、HTMLをJavaScriptなどから扱いやすい形にしたツリー構造です。
document
└─ html
├─ head
│ └─ title
└─ body
├─ h1
└─ p
JavaScriptでは、このDOMを通してHTMLの要素を取得したり、内容を変更したりできます。
const heading = document.querySelector('h1');
console.log(heading?.textContent); // "Hello"
このコードでは、HTML内の h1 要素を取得し、そのテキスト内容を表示しています。
普段のWeb開発で使う document.querySelector() や addEventListener() などは、ブラウザが作ったDOMを操作していると考えると理解しやすくなります。
ただし、Webページの表示にはHTMLだけでなく、CSSやJavaScriptも関わります。
HTMLは、見出し、段落、リンク、画像など、ページの構造を表します。CSSは、文字の大きさ、色、余白、レイアウトなど、見た目を指定します。JavaScriptは、ボタンをクリックしたときの処理や、画面の動的な変更などを担当します。
HTML → ページの構造
CSS → ページの見た目
JavaScript → ページの動き
ブラウザはHTMLを読みながら、CSSファイルやJavaScriptファイルが指定されていれば、それらも取得して処理します。そして、HTMLの構造とCSSの指定をもとに、どの要素をどの位置に、どの見た目で表示するかを計算します。
基本情報技術者試験では、HTML、CSS、JavaScriptの役割を区別して理解しておくことが重要です。
特に、HTMLはWebページの構造、CSSは見た目、JavaScriptは動的な処理、という整理はよく使います。実務でも、画面の表示崩れであればCSS、クリックしても動かない場合はJavaScript、そもそも要素が出力されていない場合はHTMLやサーバ側の処理、というように原因を切り分ける手がかりになります。
HTMLレスポンスを受け取ったブラウザは、DOMを作り、CSSやJavaScriptを組み合わせながら、最終的に私たちが見ているWebページを画面に表示します。
次の章では、HTMLの中から参照されるCSS、JavaScript、画像ファイルなどが、どのように追加で読み込まれるのかを見ていきます。
CSS・JavaScript・画像は追加で読み込まれる
ブラウザが最初に受け取る代表的なデータはHTMLです。
ただし、HTMLを1つ受け取っただけで、Webページの表示に必要なすべてのデータがそろうとは限りません。多くのWebページでは、HTMLの中からCSSファイル、JavaScriptファイル、画像ファイルなどが参照されています。
たとえば、次のようなHTMLを見てみましょう。
<!doctype html>
<html>
<head>
<link rel="stylesheet" href="/style.css">
</head>
<body>
<h1>Webページの仕組み</h1>
<img src="/logo.png" alt="ロゴ">
<script src="/app.js"></script>
</body>
</html>
このHTMLには、CSSファイル、画像ファイル、JavaScriptファイルへの参照が含まれています。
/style.css → 見た目を指定するCSS
/logo.png → 画面に表示する画像
/app.js → 動きを担当するJavaScript
ブラウザはHTMLを解析しながら、これらのファイルが必要だと判断すると、追加でHTTPリクエストを送ります。
つまり、1つのWebページを表示するために、実際には複数の通信が発生していることが多いです。
1. HTMLを取得する
2. HTML内のCSSを見つける
3. CSSファイルを取得する
4. HTML内の画像を見つける
5. 画像ファイルを取得する
6. HTML内のJavaScriptを見つける
7. JavaScriptファイルを取得する
普段ブラウザでWebページを見ていると、このような複数の通信は意識しにくいかもしれません。しかし、開発者ツールのNetworkタブを開くと、HTML、CSS、JavaScript、画像、フォント、API通信など、さまざまなリクエストが行われていることを確認できます。
実務では、この仕組みを理解しておくことがとても重要です。
たとえば、画面のデザインが崩れている場合、CSSファイルが正しく読み込まれていない可能性があります。ボタンを押しても動かない場合は、JavaScriptファイルの読み込みに失敗しているかもしれません。画像が表示されない場合は、画像のURLが間違っている、ファイルが存在しない、アクセス権限に問題がある、といった原因が考えられます。
また、読み込むファイルが多すぎたり、画像サイズが大きすぎたりすると、Webページの表示が遅くなる原因になります。Webページの表示速度を改善するときは、HTMLだけでなく、CSS、JavaScript、画像などの読み込み状況も確認する必要があります。
基本情報技術者試験では、HTML、CSS、JavaScriptの役割を区別して理解することが大切です。さらに実務では、それぞれが別ファイルとして読み込まれ、ブラウザが追加のHTTPリクエストを送って取得している、という流れまで理解しておくと役立ちます。
HTML → ページの構造
CSS → ページの見た目
JavaScript → ページの動き
画像 → ページ内に表示される素材
Webページは、1つのHTMLだけで完成しているわけではありません。ブラウザがHTMLを出発点として、必要なCSS、JavaScript、画像などを順番に読み込み、それらを組み合わせることで、私たちが見ている画面が作られます。
次の章では、PHPのようなサーバ側のプログラムが、Webページの表示にどのように関わるのかを見ていきます。
PHPの場合:サーバ側でHTMLを生成する
ここまで、ブラウザがWebサーバからHTMLを受け取り、CSSやJavaScript、画像などを追加で読み込んで画面を表示する流れを見てきました。
では、PHPのようなサーバ側のプログラムは、この流れのどこで関わるのでしょうか。
PHPは、主にWebサーバ側で実行されるプログラミング言語です。
ブラウザがPHPのコードをそのまま受け取って実行するわけではありません。
たとえば、サーバ側に次のようなPHPファイルがあるとします。
<?php
$title = 'URL入力から画面表示まで';
?>
<!doctype html>
<html>
<head>
<title><?= htmlspecialchars($title, ENT_QUOTES, 'UTF-8') ?></title>
</head>
<body>
<h1><?= htmlspecialchars($title, ENT_QUOTES, 'UTF-8') ?></h1>
</body>
</html>
このPHPコードは、Webサーバ側で実行されます。
そして、ブラウザにはPHPのコードそのものではなく、実行結果として生成されたHTMLが返されます。
ブラウザが受け取る内容は、たとえば次のようなHTMLです。
<!doctype html>
<html>
<head>
<title>URL入力から画面表示まで</title>
</head>
<body>
<h1>URL入力から画面表示まで</h1>
</body>
</html>
つまり、PHPはサーバ側でHTMLを作る役割を持っています。
ブラウザは、PHPで生成されたHTMLを受け取り、それを解析して画面に表示します。
ブラウザ
↓ HTTPリクエスト
Webサーバ
↓ PHPを実行
HTMLを生成
↓ HTTPレスポンス
ブラウザがHTMLを表示
ここで、JavaScriptとの違いも整理しておきましょう。
PHPはサーバ側で実行されることが多い言語です。データベースから記事情報を取得したり、ログイン状態を確認したり、HTMLを組み立てたりする処理に使われます。
一方、JavaScriptは主にブラウザ側で実行されます。ボタンをクリックしたときに表示を変える、入力内容をチェックする、APIからデータを取得して画面を書き換える、といった処理に使われます。
PHP → サーバ側で実行され、HTMLなどを生成する
JavaScript → 主にブラウザ側で実行され、画面の動きを担当する
ただし、最近のWeb開発ではJavaScriptをサーバ側で実行するNode.jsのような環境もあります。そのため、言語そのものだけで「必ずサーバ側」「必ずブラウザ側」と決めつけるのではなく、どこで実行されているかを見ることが大切です。
基本情報レベルでは、まず次のように理解しておくとよいです。
PHPの処理結果 → HTMLとしてブラウザに返される
ブラウザ → 受け取ったHTMLを解析して画面に表示する
実務でも、この違いを理解しておくことは重要です。
たとえば、ブラウザの「ページのソースを表示」で確認できるのは、サーバから返ってきたHTMLです。PHPの変数や処理内容そのものは、通常ブラウザからは見えません。
画面に表示される内容がおかしい場合、原因がサーバ側のPHP処理にあるのか、ブラウザ側のJavaScript処理にあるのかを切り分ける必要があります。
PHPは、Webページを表示する前の段階で、サーバ側でHTMLを生成する役割を担っています。そして、生成されたHTMLを受け取ったブラウザが、CSSやJavaScriptと組み合わせて最終的な画面を作ります。
次の章では、ここまで登場した基本情報で押さえたい用語をまとめて整理します。
基本情報で押さえたい用語まとめ
ここまで、URLを入力してからWebページが表示されるまでの流れを見てきました。
最後に、基本情報技術者試験で押さえておきたい用語を整理しておきましょう。
まず、全体の流れをもう一度簡単に振り返ると、次のようになります。
URLを入力する
↓
URLを解析する
↓
DNSでIPアドレスを調べる
↓
Webサーバへ接続する
↓
HTTPリクエストを送る
↓
HTTPレスポンスを受け取る
↓
HTML / CSS / JavaScriptを読み込む
↓
画面に表示する
この流れに沿って、それぞれの用語を整理すると理解しやすくなります。
URL
Web上のリソースの場所を示すもの。
例:https://example.com/articles
DNS
ドメイン名とIPアドレスを対応付ける仕組み。
名前解決
example.com のようなドメイン名から、IPアドレスを調べること。
IPアドレス
ネットワーク上の機器を識別するための番号。
TCP/IP
インターネットで使われる基本的な通信の仕組み。
HTTP
WebブラウザとWebサーバがデータをやり取りするためのプロトコル。
HTTPS
HTTPの通信をTLSで暗号化したもの。
HTTPリクエスト
ブラウザからWebサーバへ送る要求。
「このページをください」という依頼にあたる。
HTTPレスポンス
Webサーバからブラウザへ返す応答。
HTMLやJSON、画像などのデータが含まれる。
ステータスコード
HTTPレスポンスの結果を表す3桁の数字。
例:200、301、404、500
HTML
Webページの構造を表す言語。
CSS
Webページの見た目を指定する言語。
JavaScript
Webページに動きを加えるためのプログラミング言語。
DOM
ブラウザがHTMLを解析して作る文書構造。
JavaScriptからHTML要素を操作するときに使われる。
基本情報技術者試験では、これらの用語が単独で問われることもあります。
たとえば、「ドメイン名からIPアドレスを調べる仕組みはどれか」と聞かれれば、答えはDNSです。
また、「WebブラウザとWebサーバ間の通信に使われるプロトコルはどれか」と聞かれれば、HTTPを選ぶことになります。
ただし、実務で使うためには、用語を単独で覚えるだけでなく、流れの中で理解することが大切です。
たとえば、Webページが表示されないときに、どこで問題が起きているのかを考える場合、次のように切り分けできます。
ドメインでアクセスできない
→ DNSや名前解決の問題かもしれない
サーバに接続できない
→ IPアドレス、ポート、HTTPS設定の問題かもしれない
404が返る
→ URLのパスやルーティングの問題かもしれない
500が返る
→ サーバ側のプログラムでエラーが起きているかもしれない
画面の見た目が崩れる
→ CSSが正しく読み込まれていないかもしれない
ボタンを押しても動かない
→ JavaScriptの読み込みや実行に問題があるかもしれない
このように、基本情報で学ぶ用語は、Web開発のトラブルシューティングにもそのままつながります。
試験対策としては、まず用語の意味を正確に覚えることが大切です。
そのうえで、「URL入力から画面表示までのどの段階で使われる知識なのか」を意識すると、暗記だけでなく理解として定着しやすくなります。
Webページの表示は、DNS、TCP/IP、HTTP、HTML、CSS、JavaScriptなど、複数の技術が組み合わさって成り立っています。
それぞれをバラバラに覚えるのではなく、一連の流れとして整理しておきましょう。
実務での見方:開発者ツールで確認してみる
お疲れさまです。
ここまで、URLを入力してからWebページが表示されるまでの流れを、基本情報レベルで見てきました。
この流れは、実務ではブラウザの開発者ツールを使って確認できます。
たとえば、ChromeでWebページを開き、右クリックから「検証」を選ぶと、開発者ツールを表示できます。その中にある Network タブを見ると、ページ表示時に発生したHTTPリクエストやHTTPレスポンスを確認できます。
Networkタブを開いた状態でページを再読み込みすると、HTML、CSS、JavaScript、画像、フォント、API通信など、さまざまなリクエストが一覧で表示されます。
document → 最初に取得されるHTML
stylesheet → CSSファイル
script → JavaScriptファイル
image → 画像ファイル
fetch/xhr → JavaScriptからのAPI通信
この一覧を見ると、Webページが1つのHTMLだけで表示されているわけではなく、複数のファイルを追加で取得しながら作られていることが分かります。
特に確認したい項目は、次のようなものです。
Name → リクエストされたファイルやURL
Status → HTTPステータスコード
Type → HTML、CSS、JS、画像、API通信などの種類
Size → 取得したデータのサイズ
Time → 読み込みにかかった時間
たとえば、Status が 200 であれば、リクエストは成功しています。404 であれば、指定したURLのファイルやページが見つかっていません。500 であれば、サーバ側でエラーが起きている可能性があります。
CSSファイルが 404 になっている場合は、HTMLは表示されていても見た目が崩れることがあります。JavaScriptファイルが読み込めていない場合は、ボタンを押しても反応しない、画面の一部が更新されない、といった問題につながります。
また、API通信を確認したい場合は、fetch や xhr の種類のリクエストを見ると分かりやすいです。JavaScriptからサーバに送ったリクエストのURL、HTTPメソッド、ステータスコード、レスポンス内容などを確認できます。
たとえば、API通信が失敗している場合、次のように切り分けできます。
404 → APIのURLが間違っている可能性
401 → 認証が必要、またはログイン状態に問題がある可能性
403 → アクセス権限がない可能性
500 → サーバ側の処理でエラーが起きている可能性
このように、開発者ツールを見ると、基本情報で学ぶHTTPリクエスト、HTTPレスポンス、ステータスコード、HTML、CSS、JavaScriptといった知識を、実際のWebページ上で確認できます。
試験勉強では用語として覚える内容でも、実務では「どこで通信に失敗しているのか」「どのファイルが読み込めていないのか」「サーバから何が返ってきているのか」を調べるための道具になります。
Webページがうまく表示されないときは、まずNetworkタブを開いて、リクエストとレスポンスの状態を確認してみましょう。基本情報で学ぶ知識が、実際の原因調査にそのままつながっていることが実感できるはずです。
まとめ
この記事では、ブラウザにURLを入力してからWebページが画面に表示されるまでの流れを、基本情報技術者試験レベルで整理しました。
普段はURLを入力するとすぐにページが表示されるため、裏側の処理を意識することは少ないかもしれません。しかし実際には、次のように多くの処理が順番に行われています。
URLを入力する
↓
URLを解析する
↓
DNSでドメイン名からIPアドレスを調べる
↓
Webサーバへ接続する
↓
HTTPリクエストを送る
↓
HTTPレスポンスを受け取る
↓
HTML / CSS / JavaScriptを読み込む
↓
ブラウザが画面に表示する
URLには、通信方式、ホスト名、パス、クエリ文字列などの情報が含まれています。ブラウザはURLを解析し、アクセス先のサーバや取得したいリソースを判断します。
その後、DNSによってドメイン名からIPアドレスを調べます。コンピュータ同士の通信ではIPアドレスが必要になるため、example.com のような人間に分かりやすい名前を、通信に使えるIPアドレスへ変換する必要があります。この処理を名前解決といいます。
IPアドレスが分かると、ブラウザはWebサーバへ接続し、HTTPリクエストを送ります。サーバはそのリクエストに対して、HTMLやJSON、画像などのデータをHTTPレスポンスとして返します。
ブラウザは受け取ったHTMLを解析してDOMを作り、CSSで見た目を整え、JavaScriptで動きを加えながら、最終的なWebページを画面に表示します。また、HTML内で指定されたCSS、JavaScript、画像などは、追加のHTTPリクエストによって読み込まれます。
PHPのようなサーバ側のプログラムを使う場合は、サーバ側でPHPが実行され、その結果として生成されたHTMLがブラウザに返されます。ブラウザがPHPコードを直接実行しているわけではない、という点も重要です。
基本情報技術者試験では、DNS、IPアドレス、TCP/IP、HTTP、HTTPS、HTML、CSS、JavaScriptといった用語がそれぞれ出題されます。ただし、これらを単独で暗記するだけでなく、「URL入力から画面表示までのどの段階で関わるのか」を意識すると、理解しやすくなります。
実務でも、この流れを知っているとトラブルシューティングに役立ちます。
ドメインでアクセスできない → DNSや名前解決を確認する
ページが見つからない → URLやステータスコード404を確認する
サーバエラーが出る → ステータスコード500やサーバ側の処理を確認する
画面の見た目が崩れる → CSSの読み込みを確認する
ボタンが動かない → JavaScriptの読み込みやエラーを確認する
Webページの表示は、ブラウザ、DNS、Webサーバ、HTTP、HTML、CSS、JavaScriptなど、複数の技術が連携して成り立っています。
基本情報の学習では、用語を覚えるだけでなく、実際のWeb開発でどのように使われているのかを意識することが大切です。
今回のように一連の流れとして理解しておくと、試験対策にも実務の理解にもつながります。






コメント